
Main content
TÉMA: Český webový archiv v novém kabátku
JAROSLAV KVASNICA Jaroslav.Kvasnica@nkp.cz
BARBORA RUDIŠINOVÁ Barbora.Rudisinova@nkp.cz
Od vzniku webu v 90. letech minulého století narostl počet dokumentů publikovaných online do obrovského množství. Web se zároveň stal místem, kde se lidé přirozeně kulturně projevují. Obsah publikovaný na webu se proto stal předmětem zájmu institucí, které se starají o uchování kulturního dědictví pro další generace.
Web je svým charakterem velmi proměnlivé médium, což ovlivňuje i dokumenty publikované v jeho prostředí a zároveň to přináší obrovské výzvy pro veškeré archivační snahy. Webové stránky se neustále mění, vznikají nové a mnohé také zanikají. Typickým příkladem webových stránek, které se mění nebo zanikají, jsou zejména zpravodajské weby, časově vymezené akce a projekty, weby politických stran a uskupení a další weby s aktuálními informacemi.
Web není jen dynamické médium, ale také médium rozsáhlé – především co se týče datového objemu. To přináší enormní nároky na infrastrukturu, ať už máme na mysli kapacitu úložných zařízení či požadavky na výkon, které jsou potřeba pro zpracování velkých objemů dat. A proto se většina webových archivů vyvíjí v prostředí národních knihoven (financovaných státy), které vnímají webový obsah jako přirozenou evoluci svých fondů. S tímto jevem také souvisí zaměření webových archivů „pouze“ na národní doménu. Samozřejmě je možné najít webové archivy i v řadách univerzit či neziskových organizací, ale národní knihovny na tomto poli dominují. Velkou výjimkou potvrzující pravidlo je americká organizace Internet Archive, která se snaží o archivaci celého webu a stojí za vývojem nejpoužívanějších nástrojů v této oblasti (včetně sklízeče Heritrix a zpřístupňující aplikace Wayback Machine).
ČESKÝ WEBOVÝ ARCHIV
Vznik Českého webového archivu se datuje již do roku 2000, kdy začal být budován v rámci projektu tří spolupracujících institucí – Národní knihovny České republiky, Moravské zemské knihovny a Masarykovy univerzity. Dnes je Český webový archiv (dále jen Webarchiv) již implicitní součástí Národní knihovny ČR a kompletně jej spravuje samostatné Oddělení archivace webu.
S neustálým rozšiřováním internetu od roku 2001 se exponenciálně zvětšuje i objem dat, se kterými se Webarchiv musí vypořádat. Dnes je velikost Webarchivu přes 200 TB a při celoplošné sklizni archivujeme více než 1 200 000 domén. Z tohoto důvodu musel Webarchiv přistoupit k zavedení roční deduplikace dat v rámci jednotlivých sklizní. Sklizní je myšlen proces automatického stahování a sběru dat z vybraných webových zdrojů (vytváření kopií).
Zavedení deduplikace znamená, že se během jednoho roku kontroluje, zda nebyly digitální objekty již sklizeny v minulosti (v našem případě v rámci kalendářního roku), a pokud ano, tak se nestahují znovu, ale do metadat se umístí pouze odkaz na již jednou stažený digitální objekt. Deduplikace přinesla značnou úlevu v nárocích na objem dat – tedy na diskové kapacity. Nicméně s sebou přináší i jisté komplikace při následném zpracování dat, neboť je nutné vždy pracovat se sklizněmi v rámci celého roku.
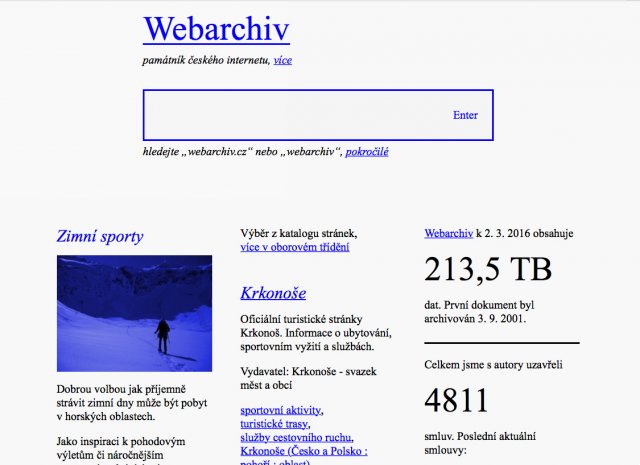
V nedávné době prošel Webarchiv celkovou proměnou vizuální identity. Tu pro Webarchiv připravili grafici Bohdan Heblík a Luboš Svoboda. Celá proměna se nese ve znamení jednoduchosti a minimalismu. Hlavním symbolem nové vizuální identity se stala modrá barva a podtržení, které bylo v počátcích internetu charakteristické pro hypertextové odkazy, a z této symboliky vychází mimo jiné i nový logotyp.

Změna vizuální identity s sebou přinesla také nové webové stránky, které jsou nyní zaměřeny zejména na uživatelskou použitelnost a představují bránu do archivu. Webové stránky jsou responzivní a fungují také na mobilních zařízeních a tabletech. Značnými změnami prošla i zpřístupňující aplikace, kterou jsme přeložili do češtiny a její vzhled přizpůsobili požadavkům našich uživatelů.
Veškerými novinkami a změnami se Webarchiv snaží co nejvíce otevřít svým uživatelům a usnadnit jim práci. To se snaží podporovat i dalšími aktivitami, jako je tvorba manuálů nebo video tutoriálů, kurátorským výběrem zdrojů na homepage a otevřenou komunikací s uživateli pomocí sociální sítě Facebook.
AKVIZICE WEBOVÝCH STRÁNEK
Akvizice zdrojů ve Webarchivu závisí na typu a účelu sklizně. Aktuálně provádíme tři typy sklizní – celoplošné, tematické a výběrové.
Cílem celoplošných sklizní je vytvoření obrazu „českého webu“ v určitém čase. Tyto sklizně jsou prováděny alespoň jednou ročně a zdrojem akvizice je v tomto případě seznam URL adres s národní doménou .cz poskytovaný správcem domény, společností CZ.NIC. Tato archivace probíhá automatizovaně a z kapacitních důvodů jsou jednotlivé adresy archivovány pouze do určité hloubky (5000 dotazů na doménu), není tedy archivováno kompletně vše, co je publikované na každé adrese.
Dalším typem jsou tzv. tematické sbírky, což jsou soubory archivovaných stránek vztahující se k určitému tématu. Jsou vybírána aktuální témata, která mají širší ohlas na internetu, například první přímá volba prezidenta nebo úmrtí Václava Havla. Kompletní přehled tematických sbírek je zveřejněný na webových stránkách Webarchivu na adrese http://webarchiv.cz/cs/tematicke-sbirky.
Oba typy sbírek jsou podle autorského zákona přístupné pouze v budově knihovny. Abychom však mohli zpřístupnit alespoň část archivu, budujeme také výběrovou sbírku, jejímž cílem je vytvořit výběrový fond webových zdrojů s historickým, kulturním či vědeckým významem a která je volně dostupná online na stránkách Webarchivu.
Novým typem sklizně, který Webarchiv chystá v příštích měsících, budou tzv. kolekce. Jedná se o novou platformu, která je běžná u zahraničních webových archivů. Kolekce jsou podobně jako tematické sklizně zaměřeny na určitou tematickou oblast, nicméně již nejsou vázané v čase a nemusí být realizovány na základě aktuálních událostí. Sklízení webových zdrojů v kolekci bude probíhat periodicky, podobně jako u sklizní výběrových. Hlavní myšlenkou kolekcí je pravidelně archivovat určitou odbornou oblast (např. nejvýznamnější oborové webové zdroje) nebo oblast zájmu (např. webové zdroje věnované sametové revoluci), případně zdroje vázané na stát či instituci (např. webové zdroje v rámci univerzity).
První velkou kolekci přináší nově navázaná spolupráce s Univerzitou Karlovou, se kterou nyní vytváříme seznam webových zdrojů (v blízké době dojde ke spuštění první sklizně této kolekce).
Nové zdroje do výběrové sbírky volí nejčastěji přímo kurátoři Webarchivu. Při budování fondu elektronických zdrojů Webarchivu je používána, stejně jako v celé Národní knihovně, metoda Konspektu. V rámci Konspektu jsou zdroje rozděleny do předmětových kategorií. Metoda je vhodná pro snadnější uživatelskou orientaci ve zdrojích, v oblasti webových zdrojů má však určitá omezení, například nutnost zařazení jednoho zdroje zabývajícího se více tématy pouze do jedné předmětové kategorie na základě převládajícího obsahu. V každé základní předmětové kategorii Konspektu jsou vytvářeny priority a podle nich je tak budován seznam zdrojů, například v předmětové kategorii Politické vědy jsou jako nejvyšší priority vybrány stránky ministerstev, státních úřadů, parlamentních politických stran, v dalším pořadí to jsou politologické ústavy vysokých škol, odborné časopisy, další politické strany atd.
V oblasti akvizice spolupracuje Webarchiv také s Českým národním střediskem ISSN. Středisko ISSN nám pravidelně zasílá seznam periodik, jejichž vydavatelé žádají o přidělení čísla ISSN pro elektronické časopisy a souhlasí se zařazením do Webarchivu.
Navrhování zdrojů do Webarchivu je však otevřené i pro širokou veřejnost. Prostřednictvím formuláře na adrese http://webarchiv.cz/cs/pridat-web může kdokoliv navrhnout stránky, které bychom měli archivovat. Aktuálně bychom v oblasti navrhování zdrojů rádi navázali spolupráci s dalšími knihovnami a institucemi – zejména odborné knihovny mají přehled o významných elektronických zdrojích v konkrétních oblastech.
Všechny takto navržené zdroje jsou hodnoceny kurátory Webarchivu, zda po obsahové stránce splňují stanovená kritéria (preferovány jsou unikátní zdroje s historickou, kulturní či vědeckou hodnotou) a zda je bude možné archivovat i po technické stránce. V případě schválení je zahájena komunikace s vydavatelem zdroje za účelem získání souhlasu s archivací a s online zpřístupněním archivovaných verzí. Ne vždy se nám však souhlas s archivací vybraného zdroje podaří získat, vydavatel často na naši nabídku nereaguje nebo ji přímo odmítne. Vzhledem k tomu, že zpřístupnění funguje na dobrovolné bázi, množství významných zdrojů, které bychom rádi do výběrové kolekce zařadili, bohužel stále chybí. Na základě souhlasu s vydavateli aktuálně zpřístupňujeme online téměř 5000 zdrojů.
VEŘEJNÝ VS. CHRÁNĚNÝ (DARK) ARCHIV
Zpřístupnění archivních dat z Webarchivu je omezeno autorským zákonem. Archivace je vymezena tzv. knihovní licencí tohoto zákona, kdy je knihovnám povoleno vytvářet elektronické kopie dokumentů pro archivní účely. Tyto archivní kopie v elektronické podobě mohou být však zpřístupněny pouze v budově knihovny. V Národní knihovně jsou tak data z celého Webarchivu, tedy i celoplošných sklizní a tematických sbírek, zpřístupněna na terminálech v Referenčním centru v Klementinu. Aby mohla být data z výběrové sbírky zpřístupněna online na našem webu, potřebujeme získat souhlas vydavatele s tímto zpřístupněním. Ten je možné realizovat buď podepsáním smlouvy s Národní knihovnou, nebo pak jednodušší, avšak méně často využívanou variantou – vystavením stránek pod licencí Creative Commons.
PŘÍSTUP DO ARCHIVU
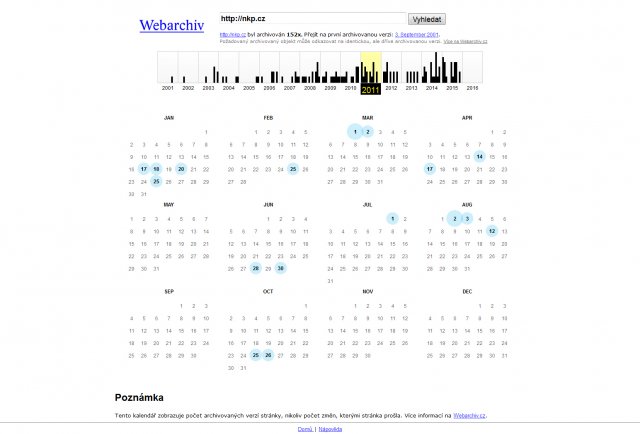
Při vytváření nového vzhledu stránek Webarchivu jsme se rozhodli vyhledávání co nejvíce zjednodušit. K vyhledávání slouží vyhledávací pole, které je dominantní částí úvodní stránky webu. Vyhledávat lze podle URL adresy stránek, kterou je možné zadat v libovolném platném tvaru (např. http://nkp.cz, www.nkp.cz nebo pouze nkp.cz). Kromě URL adresy je možné vyhledávat také pomocí libovolných klíčových slov, v tomto případě jsou prohledávány názvy stránek a jejich anotace. Výstupem je pak seznam nalezených výsledků.
Druhým způsobem, jak vyhledávat zdroje Webarchivu, je prohlížení katalogu stránek, který je dostupný na adrese http://webarchiv.cz/cs/katalog-stranek. Katalog je členěný do předmětových skupin podle metody Konspektu a má dvouúrovňovou hierarchii. Vybrat je možné ze dvou režimů zobrazení – buď jednoduchého vizuálního, kde jsou zobrazeny pouze náhledy stránek a jejich názvy, nebo podrobnějšího textového, kde jsou uvedeny i popisné údaje (jako je URL adresa stránek, vydavatel, anotace a klíčová slova). Tento způsob vyhledávání je vhodnější pro uživatele, kteří nehledají konkrétní stránku, ale například informace na určité téma.

V neposlední řadě lze zdroje z Webarchivu vyhledat také prostřednictvím katalogu Národní knihovny. Pro všechny zdroje zařazené do výběrové sbírky Webarchivu jsou vytvářeny katalogizační záznamy, které obsahují také odkaz na archivované verze.
Po vyhledání požadovaného zdroje nebo jeho výběru z katalogu je uživatel přesměrován do rozhraní aplikace OpenWayback, což je aplikace pro zobrazení dat z webových archivů. Navigace v tomto rozhraní je jednoduchá a intuitivní, pro každý zdroj se zobrazí časová osa a kalendář s vyznačenými daty archivace a uživatel tak může snadno zobrazit požadovanou verzi.
ZÁVĚR – BUDOUCNOST
Zaměření a činnost Webarchivu je v rámci českého knihovnictví unikátní. Většina publikovaného obsahu se dnes již přesouvá do webového či všeobecně elektronického prostředí a český webový archiv umožňuje tato data zachovat a chránit před ztrátou. Lze předpokládat, že význam webových archivů bude do budoucna stále narůstat. Webarchiv Národní knihovny ČR, který vznikl v roce 2000, je také jedním z nejstarších webových archivů v Evropě a jako jediný archiv nejlépe pokrývá zdroje s českou národní doménou .cz.
Naším cílem do budoucna je budování kompletního archivu českých webových zdrojů (jež budou dlouhodobě uložené), který bude v co největším rozsahu dostupný pro uživatele, s plnotextovým vyhledáváním a s rozhraním pro práci s obsahovými i popisnými metadaty.